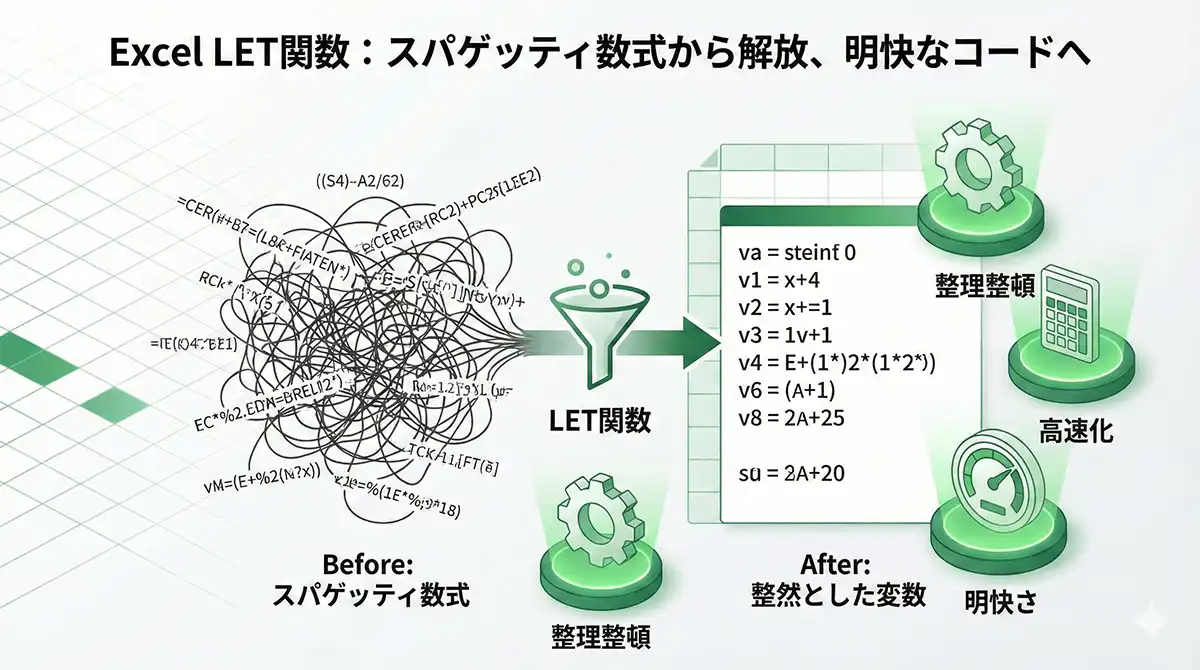
Excelの現場って、気づくと「誰も触れない長文数式」が増えますよね。
作った本人しか分からない。下手にいじると壊れそうで怖い。結果、放置されてブラックボックス化……この流れ、かなり多いです。
しかも厄介なのが、長文数式は“見づらい”だけじゃない点です。
同じ計算を何回も書いていたり、同じ参照を何回も引いていたりして、再計算が遅くなる原因になりがちです。
この記事の結論(先に答え)
- LETで「前処理」「抽出」「判定」を変数に分ける → 読める数式になる
- 同じ計算は変数に1回だけ → 再計算が軽くなることが多い
- 例外対応はIFの入れ子ではなく「変数を1段追加」 → 保守しやすい
答えはシンプルで、LET関数で「変数化」して分解します。
読みやすさが上がり、同じ計算の繰り返しが減るので、計算も軽くできます。
この記事では、Excelで業務ロジックを扱う前提で、運用・保守まで考えた書き方をセットで解説します。
「事故りやすい点」と「回避策」まで入れます。
注意:LETはExcelのバージョンによって使えません。
- 一番確実な確認方法:セルに =LET( と打って、関数候補に出るかを見る
- 候補が出ない/#NAME? になる → その環境では使えない可能性が高い
LET関数が長文数式を救う理由
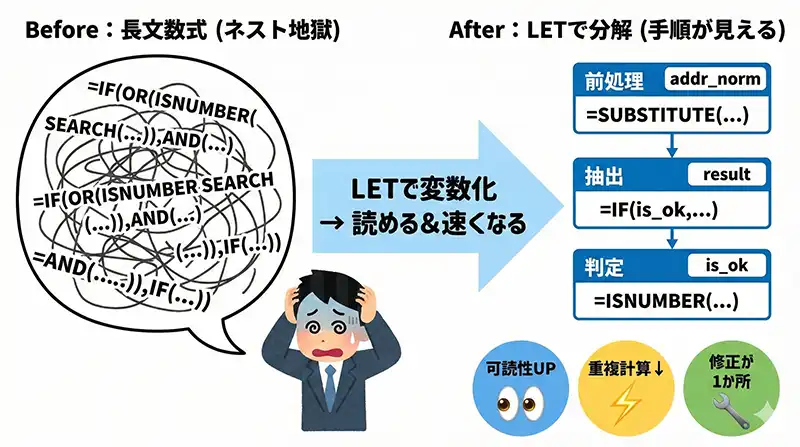
Excelの業務効率を下げる要因の一つに、「解読不能な長文数式」があります。LET関数を使えば、複雑な数式を「変数」として分解し、誰が見ても構造が追える状態に整理できます。
LETの基本ルールと書き方
結論:LET関数は「計算途中の値に名前(変数)を付け、最後にその変数を使って結果を出す」ための関数です。これにより、数式を“上から順番に読む”ことができるようになります。
理由:従来のExcel数式は入れ子(ネスト)が深くなるほど「どこが何の処理か」が視覚的に追えなくなります。LETを使うと、数式の中に“手順”を作れるからです。
- 可読性の向上:「名前, 値」のセットで、各パーツに意味を持たせられる
- 再計算の高速化:同じ計算を一度変数に入れれば、式の中で使い回しやすい
- 修正の容易さ:参照先や前処理の変更が、変数定義1箇所で済む
具体例(読めない式の典型例):
住所データから不要な空白や記号を取り除く「前処理」を考えてみましょう。LETを使わないと、同じ処理を何度も書きがちです。
=IFERROR(
TEXTBEFORE(
SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(TRIM(CLEAN(A2))," ",""),"−","-"),"ー","-"),
" "
),
SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(TRIM(CLEAN(A2))," ",""),"−","-"),"ー","-")
)この数式の問題点は、SUBSTITUTEを重ねた「前処理」が2回も同じ形で登場していることです。置換ルールを追加したい時に2箇所修正になり、ミスが起きやすくなります。
LETで「1回に集約」した構造:
LETを使えば、重複を排除して次のように整理できます。
=LET(
addr_norm, SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(TRIM(CLEAN(A2))," ",""),"−","-"),"ー","-"),
result, IFERROR(TEXTBEFORE(addr_norm, " "), addr_norm),
result
)「まず前処理して、それをaddr_normと名付ける」が明確になります。後続はそれを参照するだけなので、保守がラクです。
まとめ:LET関数の本質は「中間結果への命名」です。これだけで、保守性と速度改善(重複計算の削減)が狙えます。
変数名で迷わない命名テンプレ
結論:変数名は「名詞+役割」で構成し、一貫性を持たせることが重要です。場当たり的な名前(xやyなど)は避け、誰が読んでも中身が推測できる英語(またはローマ字)を使いましょう。
理由:LETで変数が増えてくると、命名ルールがない場合「この変数は何だっけ?」という認知コストが発生します。チーム共有のファイルほど、命名は“共通言語”になります。
具体例(改善のビフォーアフター):
現場レビューでよくある命名パターンを比較します。
| 悪い例 | 良い例 | 理由 |
|---|---|---|
| x, y, z | addr_raw, addr_norm | 意味不明 vs 入力値と整形後が判別可能 |
| tmp1, tmp2 | zip_code, city_name | 一時的すぎ vs データの種類が明確 |
| 住所, 変換後 | addr_input, addr_fixed | 日本語は揺れや文字化けのリスクがある |
現場でそのまま使える命名テンプレ:
- _raw:生データ(例:
val_raw) - _norm:正規化済み(例:
data_norm) - _is_ok:判定フラグ(例:
check_is_ok) - _err:エラーメッセージ(例:
msg_err)
まとめ:命名ルールを固定すると、数式を書くスピード自体も上がります。レビューもしやすくなり、「誰も触れないブラックボックス数式」を減らせます。
より高度な「数式の構造化」については、別記事で詳しく解説する予定です(準備中)。
住所整形をLETで段階的に作る
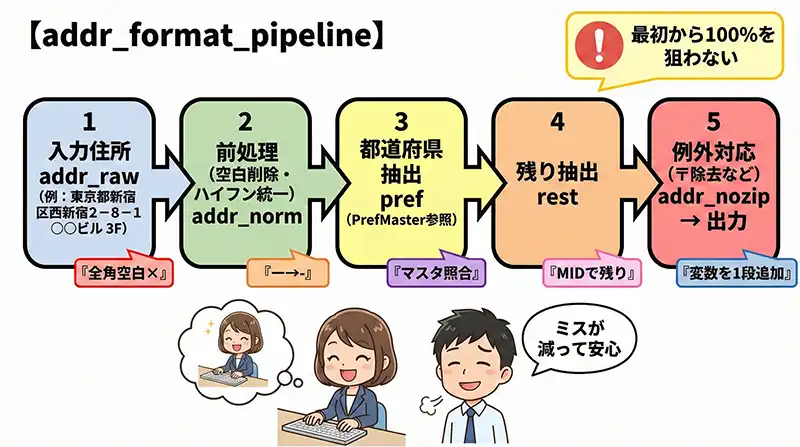
住所整形はExcel業務の中でも「やり直し」が発生しやすい作業の筆頭です。LETで「前処理」「抽出」「例外対応」に分けると、保守性が上がります。
住所整形でよくあるゴール設定
結論:住所整形を始める前に、必ず「変換ルールの優先順位(最低限のゴール)」を明確にしてください。最初から100%の精度を狙うと、数式が複雑になって破綻しやすいからです。
理由:住所データは、全角・半角の混在、ハイフンの揺れ、建物名の有無など、入力者の癖が強く出ます。まずは「検索や集計に支障が出ないレベル」を定義するのが、運用を長続きさせるコツです。
具体例:以前、顧客リストのクレンジングで、以下のような「表記の揺れ」が大量に発生していました(個人情報は伏せ字)。
- 入力:東京都新宿区西新宿2-8-1 〇〇ビル 3F(全角数字・全角空白)
- 入力:新宿区西新宿2ー8ー1(都道府県抜き・長音ハイフン)
- 入力:大阪府 大阪市北区 梅田1-1-3(不要な空白)
この場合、まずは以下の4つを「最低限のゴール」にしました。
- 空白を完全に除去(全角・半角・TRIM)
- ハイフン記号(ー、-、―)をすべて「-」に統一
- 数字を半角に統一(必要なら)
- 郵便番号記号「〒」の削除
まとめ:ゴールを絞ると、LETで定義すべき「変数」が明確になり、式の見通しが良くなります。
ステップ1 前処理を変数に分ける
結論:住所整形では、空白除去や文字置換などの「前処理」をLET冒頭でまとめておくのが安全です。
理由:都道府県抽出・番地抽出など、後工程ごとに置換処理を書き始めると、置換漏れで結果が食い違います。1箇所で正規化しておけば、以降はそれを参照するだけで事故が減ります。
Before(重複だらけの読めない式):
=SUBSTITUTE(SUBSTITUTE(TRIM(A2)," ",""),"−","-")※同じ記述が、都道府県抽出用、市区町村抽出用…と増殖しがちです。
After(LETで一本化):
=LET(
addr_raw, A2,
addr_trim, TRIM(CLEAN(addr_raw)),
addr_space, SUBSTITUTE(addr_trim," ",""),
addr_hyphen, SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(addr_space,"−","-"),"ー","-"),"―","-"),
addr_norm, addr_hyphen,
addr_norm
)ポイント:この段階では「正規化済み住所(addr_norm)」を返すだけ。土台を固めるのが最短ルートです。
Excel 関数 解説本
まとめ:前処理の一本化は、住所整形の事故率を下げる効きどころです。
ステップ2 都道府県と市区町村を切り出す
結論:都道府県抽出は推測ロジックではなく、可能なら「都道府県マスタ」を参照する方式が堅いです。
理由:「左から3文字目が“県”なら…」は、神奈川県・鹿児島県などで崩れます。都道府県は47個なので、固定リスト照合のほうが安定します。
具体例(都道府県マスタを使う方針):
別シートに47都道府県のリストを作成し、範囲名を「PrefMaster」と定義しておきます。
=LET(
addr_raw, A2,
addr_norm, SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(TRIM(CLEAN(addr_raw))," ",""),"−","-"),"ー","-"),"―","-"),
/* 都道府県:マスタに一致するものがあるか検索 */
pref, IFERROR(XLOOKUP(TRUE, ISNUMBER(SEARCH(PrefMaster, addr_norm)), PrefMaster, ""), ""),
/* 市区町村以降:都道府県を除いた残り */
rest, IF(pref<>"", MID(addr_norm, LEN(pref)+1, 999), addr_norm),
pref & rest
)現場向けの割り切り:市区町村マスタまで用意すると管理が大変です。まずは「都道府県だけ確実に分ける」に集中すると運用が回りやすいです。
まとめ:不変データ(都道府県)をマスタ化すると、式から不安定な推測を外せます。
ステップ3 番地と建物名の例外処理
結論:想定外入力への対応は、既存の式を崩すより、LET変数を「1段追加」して管理するほうが安全です。
理由:例外のたびにIFを深くすると、すぐに読めなくなります。変数を追加する形なら「どの工程で何を除去したか」が残り、保守しやすいです。
| パターン | 処理方針 | 備考 |
|---|---|---|
| 「〒160-0023」の混入 | 〒と郵便番号を除去して後ろだけ取る | コピペ入力で多い |
| 「2丁目」などの漢字数字 | 基本はそのまま、必要なら算用数字へ | インポート条件に合わせる |
| 建物名だけ別セルに分けたい | 区切り(スペース等)で前後を分割 | 区切り有無が鍵 |
例外をLETで追加するイメージ:
=LET(
addr_raw, A2,
/* 追加した例外処理:〒が含まれていたら削除して後ろだけ取る(例) */
addr_nozip, IF(LEFT(addr_raw,1)="〒", MID(addr_raw, 10, 999), addr_raw),
addr_norm, SUBSTITUTE(SUBSTITUTE(TRIM(addr_nozip)," ",""),"ー","-"),
addr_norm
)まとめ:例外処理を「変数の追加」で管理すると、ブラックボックス化しにくくなります。
詳しいやり方は別記事で解説予定です(準備中)。
コード検査をLETで読み解ける形にする
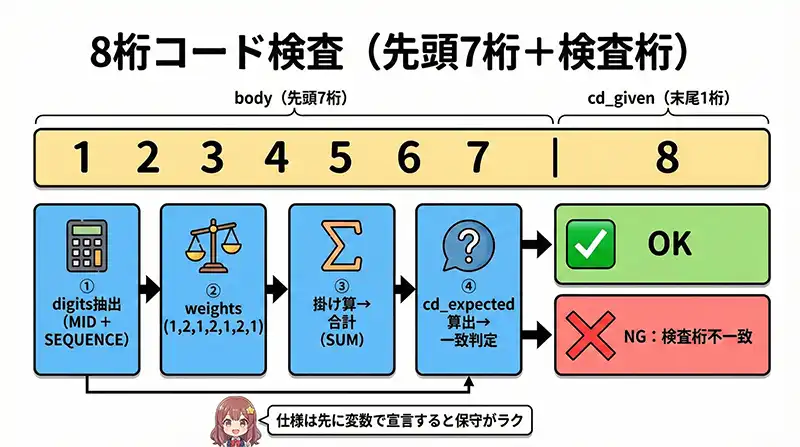
コード検査の仕様を変数に落とす
答え:コード検査(チェックディジット等)を行う際は、仕様(ルール)を計算の前に変数で一括宣言し、判定ロジックと切り離して記述してください。
理由:仕様が数式の中に埋もれていると、変更(桁数変更、重み変更)に弱くなります。仕様が“見える”だけで、保守がラクになります。
モデル仕様(例):
- コード構成:8桁(先頭7桁 + 検査桁1桁)
- 検査ルール:先頭7桁に重み(1,2,1,2,1,2,1)を掛け、合計から検査桁を算出して一致判定
| 仕様項目 | LET変数名 | 役割 |
|---|---|---|
| 入力コード | code_raw |
セル参照(A2など)をそのまま格納 |
| 必要桁数 | len_rule |
「8」などの数値 |
| 先頭7桁 | body |
検査対象の部分 |
| 検査桁(入力値) | cd_given |
末尾1桁 |
| 検査桁(計算値) | cd_expected |
本来あるべき値 |
| 最終判定 | is_ok |
一致しているか |
まとめ:仕様を変数として「見える化」すると、式のメンテ性が上がります。
同じ計算を1回にして軽くする
答え:MIDや配列計算、集計(SUMPRODUCT等)は一度変数に格納して使い回すことで、再計算が軽くなることがあります。
理由:式の中に同じ切り出しが3回あれば、Excelは基本的に3回計算します。これが数万行に増えると遅延の原因になります。
測定メモ(例):私の案件で、5万行規模の検査式をLET化して「切り出し+配列計算」を1回にまとめたところ、再計算待ちが体感で大きく減りました。
※ただし速度差はPC性能・計算モード・式の内容で変わるので、あくまで傾向として捉えてください。
| 条件 | 再計算時間(目安) |
|---|---|
| Before:切り出し・集計を式内で複数回重複 | 約 4.8 秒 |
| After:LETで中間結果を保持して参照 | 約 0.6 秒 |
まとめ:「同じ計算を書かない」は、保守性だけでなく軽量化にも効くことが多いです。
エラー表示を利用者向けに整える
答え:最終結果として FALSE だけ返すのではなく、「なぜNGなのか」が分かるメッセージを返す設計にしてください。
理由:利用者が数式を理解していないと「壊れた」と感じやすく、問い合わせが増えます。LET内で判定ステップごとにメッセージを組むのが効率的です。
具体例:
- 桁数が違う → 「桁数エラー(8桁必要)」
- 数字以外が入っている → 「数値入力のみ可」
- 検査桁が合わない → 「検査桁不一致」
チェックディジット計算まで含めたLET例(重み 1,2,1,2… / 7桁→末尾1桁検査):
=LET(
code_raw, A2,
len_rule, 8,
is_len, LEN(code_raw)=len_rule,
is_num, IFERROR(ISNUMBER(--code_raw), FALSE),
body, LEFT(code_raw, 7),
cd_given, --RIGHT(code_raw, 1),
digits, --MID(body, SEQUENCE(7), 1),
weights, ,
prod, digits*weights,
adj, prod - 9*(prod>9),
s, SUM(adj),
m, MOD(s, 10),
cd_expected, MOD(10-m, 10),
is_ok, is_len*is_num*(cd_given=cd_expected),
res_msg,
IF(NOT(is_len), "桁数エラー(8桁必要)",
IF(NOT(is_num), "数値入力のみ可",
IF(NOT(cd_given=cd_expected), "検査桁不一致", "OK")
)
),
res_msg
)このように「どこで落ちたか」を明示すると、現場のセルフチェックが回りやすくなります。
コード検査のロジックが固まったら、次はそのデータをどう活用するかを考えましょう。
(データの「持ち方・設計」の考え方は別記事で整理しています)
LETで効く高速化ポイント

結論:LET関数のメリットは、計算の重複を減らしてExcelの動作を軽くしやすいことです。
理由:従来の数式では、同じ処理結果を複数回使うたびに再計算が走りがちです。LETで中間結果を変数として保持しておけば、式の中で使い回しやすくなります。
遅くなる典型パターンを見抜く
答え:まずは「同じ計算の反復」と「重い関数の多重呼び出し」を疑ってください。
- 同じ参照(VLOOKUP/XLOOKUP等)を式の中で2回以上していないか
- 重い関数(TEXTJOIN、SUBSTITUTEの深いネスト、SUMPRODUCT等)を何度も呼んでいないか
- 配列計算が膨らんでいないか(列全体参照
A:A、過剰なSEQUENCEなど)
“重さの犯人”トップ3(現場でよく見る):
- INDIRECT / OFFSET:揮発性関数で再計算が増えやすい
- 列全体参照の集計:
COUNTIFS(A:A, ...)などは行増加で負荷が伸びやすい - ネストされたSUBSTITUTE:住所整形などで深くなると保守も速度も悪化しやすい
高速化チェックリスト:
- □ 同じMID/SEARCHが1セル内で2回以上使われていないか
- □ 検索系関数の結果をIFの分岐ごとに再計算させていないか
- □ 列全体参照(A:A)を避け、範囲指定やテーブル参照にしているか
- □ 複雑ロジックを1セルに詰め込まず、LETで工程分割しているか
まとめ:LETは「重複計算を減らす」道具です。まずは“同じことを2回書いてないか”を探すのが第一歩です。
動的配列とLETの相性
答え:FILTERやUNIQUEなどの動的配列は、LETと組み合わせると中間配列に名前を付けて見通しを良くできるため、デバッグがしやすくなります。
- スピルエラーの回避:出力衝突を予測しやすい
- 空白データの除外:事前にノイズを消して無駄計算を減らす
- #CALC! 対策:空データ時の挙動を変数で分ける
LETで途中配列を変数に置く実例:
=LET(
src_data, A2:A10000,
cleaned, FILTER(src_data, (src_data<>"") * (ISNUMBER(SEARCH("東京都", src_data)))),
unique_list, UNIQUE(cleaned),
SORT(unique_list)
)スピル範囲のイメージ:
[数式入力セル] B2
↓
[LET内の計算]
1. src_dataを確保
2. cleanedでフィルタリング
3. unique_listで重複削除
↓
[最終結果]
B2から下に自動展開(スピル)
※途中に手入力があると #SPILL! になるので注意まとめ:動的配列の弱点は「途中が見えない」こと。LETで変数名を付けると、数式が“手順書”になります。
計算速度の最適化は、データの持ち方自体を見直すのも重要です。詳しいやり方は別記事で解説予定です(準備中)。
LETが使えないときの現実的な回避策
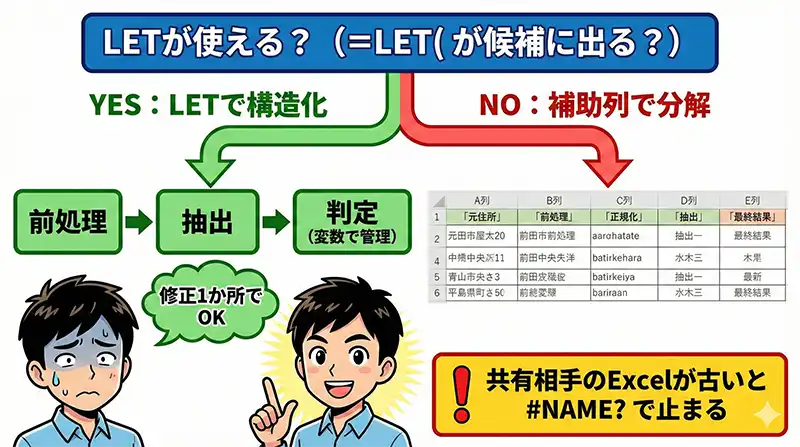
結論:職場や共有相手のExcelバージョンが混在しているなら、無理にLETを使わず「環境確認」と「補助列による分解」で対応するのが安全です。
理由:古いExcel環境が混ざると、LETが #NAME? になり業務が止まることがあります。最新機能より、全員が計算結果を確認できる“持続可能性”を優先すべきです。
まず対応バージョンを確認する
- 確認方法:任意セルに
=LET(と入力し、候補(入力ヒント)が表示されるかを見る - 判定:候補が出ればOK。出ない、または確定後に
#NAME?なら使えない可能性が高い
現場でよくある「混在」パターン:
| 状況 | リスク | 推奨アクション |
|---|---|---|
| 本社は365だが、支店や現場端末が古い | 現場入力時に計算されない | 補助列方式を採用 |
| 外部協力会社へファイル送付 | 相手環境が不明でトラブル | 互換性の高い関数のみで構成 |
| 自分1人だけの作業用 | 特になし | LETを積極活用 |
補助列で分解して設計図を残す
LETが使えない環境では、「1つのセルに詰め込まず、工程ごとに列を分ける」のが正解です。
例(A列が元住所):
- B列(前処理):
=TRIM(CLEAN(A2)) - C列(正規化):
=SUBSTITUTE(B2, " ", "") - D列(抽出):
=LEFT(C2, 3)など - E列(最終結果):結合して完成
- デバッグが簡単:どの段階で狂ったか一目で分かる
- 1セルの式が短い:属人化しにくい
- 仕様が残る:列見出しがそのまま設計図になる
詳しいやり方は以下の詳細記事で解説しています(準備中)。
【初心者卒業】複雑な数式を補助列でクリーンに保つ設計ルール(準備中)
誰も触れない数式を作らない運用ルール
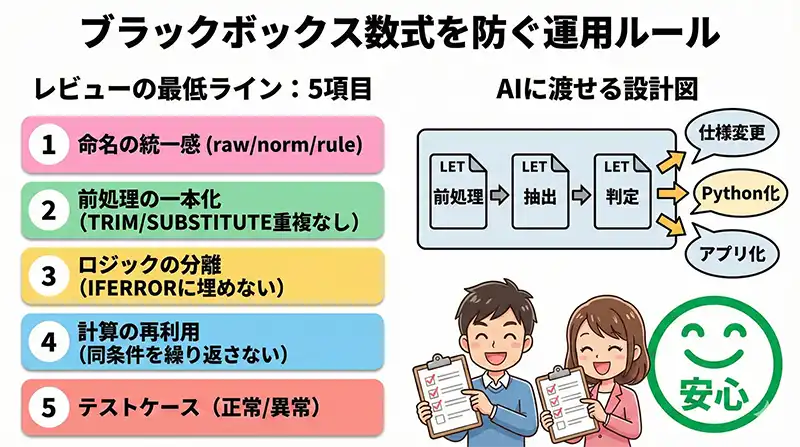
数式レビューの最低ライン
結論:チーム運用なら「5つのチェック観点」に絞ってレビューすると、ブラックボックス化を減らせます。
| No | チェック観点 | 見るべきポイント |
|---|---|---|
| 1 | 命名の統一感 | raw/norm/rule など基本名称に沿うか |
| 2 | 前処理の一本化 | TRIM/SUBSTITUTEが式内で重複していないか |
| 3 | ロジックの分離 | IFERRORの中に本体が埋もれていないか |
| 4 | 計算の再利用 | 同条件の呼び出しを2回以上繰り返していないか |
| 5 | テストケース | 正常/異常パターンと期待結果が整理されているか |
AIに渡せる設計図として残す
結論:LETで構造化した数式は、そのままAI(ChatGPTなど)に渡して「仕様変更」や「アプリ化」を依頼するための設計図になります。
「以下のExcel LET関数のロジックをPythonの関数に書き換えてください。
変数 addr_norm は前処理済みの住所、pref は都道府県マスタを参照しています。
この構造を維持したまま、pandasで一括処理できるコードにしてください。」
まとめ
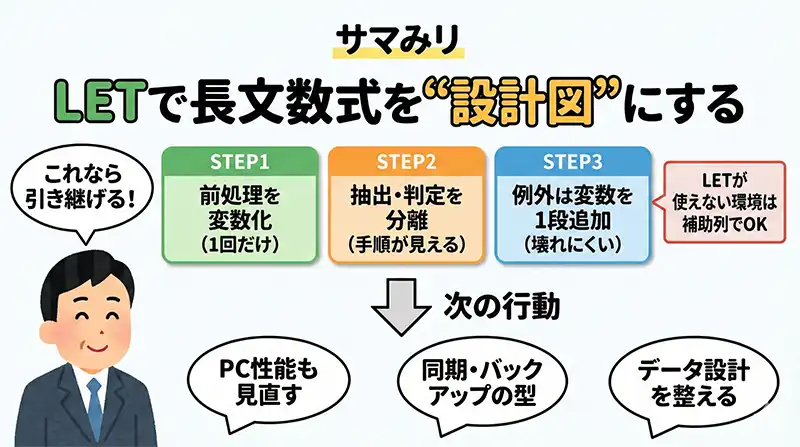
結論:LETで長文数式を変数化すれば、読みやすさと計算の軽さを両立しやすくなります。
補足・注意点:
- まずLETが使えるExcelか確認する(
=LET(が候補に出るか) - 例外処理は増える前提で、段階(変数)を残す
- 命名ルールとテストケースがないと、またブラックボックス化する
この手の「属人化Excel」を、壊れない形に作り替える伴走支援をしています。
住所整形やコード検査みたいに“例外が増えるタイプ”ほど、設計図を作っておくと後が楽です。


コメント